
How to Teach a Turtle to Balance a Bamboo
Discretization and Environment Customization in Gymnasium


Recap
In my previous post about Gymnasium, “How to Teach an Agent to Reach a Cookie”, we explored the basics of reinforcement learning using Gymnasium’s simple pre-built environment — CliffWalking. If you’re not familiar with Gymnasium, I recommend checking out that article before diving into this one.
Agenda
Today, we’re taking our RL journey a step further by tackling two crucial aspects of practical reinforcement learning: discretization and environment customization. These concepts serve as essential bridges between theoretical RL and real-world applications.
Discretization allows us to simplify complex, continuous state spaces into manageable discrete representations — making many problems tractable for traditional RL algorithms. Meanwhile, environment customization gives us the power to adjust existing environments to match our specific needs or even create entirely new ones from scratch.
In this post, we’ll leverage these powerful tools to transform the classic CartPole environment into our own creation: TurtleBamboo — where we will use discretization and Q-Learning to teach this turtle to balance a bamboo stick on his shell.

CartPole — Balancing Act
CartPole is one of Gymnasium’s classic control environments. Unlike our grid-based CliffWalking from the previous post, CartPole throws us into the world of physics and continuous states.
The Gymnasium’s version corresponds to the version described by Barto, Sutton, and Anderson in “Neuronlike Adaptive Elements That Can Solve Difficult Learning Control Problem”. A pole is attached by an un-actuated joint to a cart, which moves along a frictionless track. The pendulum is placed upright on the cart and the goal is to balance the pole by applying forces in the left and right direction on the cart.
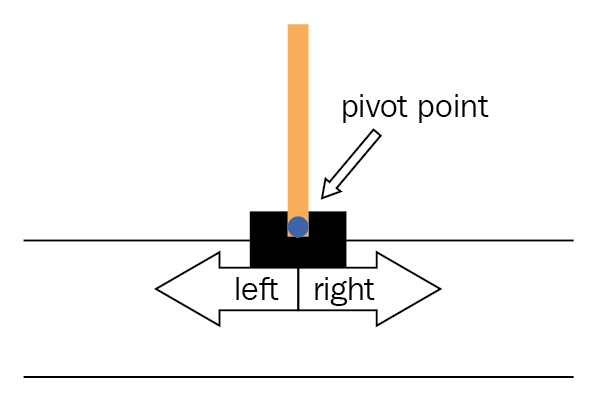
The environment tracks four continuous values: cart position, cart velocity, pole angle, and pole angular velocity. Your agent can only do two things — push left or right. Each time step you keep the pole upright, you get a reward of +1. The episode ends when the pole falls too far (±12°), the cart moves out of bounds (±2.4 units), or you reach the maximum score of 500.
the full details could be found at the CartPole Environment's Documentation.
Here’s what happens with random actions:
import gymnasium as gymenv = gym.make("CartPole-v1", render_mode="human")
state, _ = env.reset()
terminated = truncated = False
total_reward = 0while not terminated and not truncated:
action = env.action_space.sample() # Random push left or right
state, reward, terminated, truncated, _ = env.step(action)
total_reward += rewardprint(f"Total Score={total_reward}")You can run it for yourself and see that random actions usually earn a measly 20–30 points before the pole topples over.
So why transform this into TurtleBamboo? Well, a turtle balancing bamboo is way more fun to visualize than an abstract cart and pole, and if you read my previous post “Three Lovely Projects And One Failure”, you should be familiar with my love for turtles.
Plus, it gives us a perfect opportunity to show how you can customize Gymnasium environments while keeping the core challenge intact.
The Basics of Environment Customization
One of the powerful aspects of Gymnasium is how easily you can customize existing environments. When building real-world reinforcement learning applications, you’ll rarely use environments straight out of the box — you’ll need to tailor them to your specific problems.
In Gymnasium, there are several ways to customize environments:
Complete customization: Building an environment from scratch by implementing the Gymnasium interface
Wrapper-based customization: Using wrappers to modify observations, actions, rewards, etc.
Inheritance-based customization: Inheriting from an existing environment and overriding specific methods
For our TurtleBamboo environment, we’re taking the third approach — inheriting from CartPole and customizing primarily the rendering while keeping the underlying physics intact.
from gymnasium.envs.classic_control.cartpole import CartPoleEnv
class TurtleBambooEnv(CartPoleEnv):
"""CartPole with turtle and bamboo visuals"""
metadata = {"render_modes": ["human", "rgb_array"], "render_fps": 50}
def __init__(self, render_mode=None):
super().__init__(render_mode=render_mode)
def render(self):
# TODOBy inheriting from CartPoleEnv, we maintain all the physics, state transitions, and core functionality of the original environment. This approach lets us focus solely on the visual representation.
And now we just need to write the render function, where we will transform the Cart into Turtle and the pole into Bamboo Stick.
The Artistic Journey — Turtle and Cucumber
I should confess — I’m not much of a digital artist! My original plan was to create a turtle balancing a cucumber (which, let’s be honest, would have been adorable). I even asked ChatGPT for help, generating some cute images. But they weren’t quite usable here — I needed exact proportions and a way to adjust them easily if needed.
Anyway, you can enjoy them too:



After moments of despair, I tried again with cursor, and this time it generated the images with pygame. The game looked much better, with everything in the correct proportions. At first, I struggled to render a cucumber, but what I got instead were sticks that looked a lot like bamboo. So, I adjusted my plan accordingly — and honestly, it was probably for the better!
I won’t include the code here since it’s not the most interesting part, but the end result was usable images for turtle and bamboo.

Next up, let’s integrate these assets into the render function and bring TurtleBamboo to life!
Bringing TurtleBamboo to life
Now that we have the assets, let’s load the images and scale them to the correct proportions:
import os
import gymnasium as gym
from gymnasium.envs.classic_control.cartpole import CartPoleEnv
from gymnasium.error import DependencyNotInstalled
class TurtleBambooEnv(CartPoleEnv):
"""CartPole with turtle and bamboo visuals"""
metadata = {"render_modes": ["human", "rgb_array"], "render_fps": 50}
def __init__(self, render_mode=None):
super().__init__(render_mode=render_mode)
self.turtle_img = self.bamboo_img = None
self._pygame_initialized = False
# Setup assets directory if needed
assets_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), "assets")
if not os.path.exists(assets_dir):
os.makedirs(assets_dir, exist_ok=True)
from generate_assets import generate_pixel_art
generate_pixel_art(scale=2)
def _initialize_pygame(self):
try:
import pygame
from pygame import gfxdraw
except ImportError as e:
raise DependencyNotInstalled(
'pygame is not installed, run `pip install "gymnasium[classic-control]"`'
) from e
if self.screen is None:
pygame.init()
if self.render_mode == "human":
pygame.display.init()
self.screen = pygame.display.set_mode(
(self.screen_width, self.screen_height)
)
else:
self.screen = pygame.Surface((self.screen_width, self.screen_height))
if self.clock is None:
self.clock = pygame.time.Clock()
assets_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), "assets")
# Load turtle
self.turtle_img = pygame.image.load(os.path.join(assets_dir, "turtle.png"))
self.turtle_img = pygame.transform.scale(self.turtle_img, (50*2, 50*2))
# Load bamboo
self.bamboo_img = pygame.image.load(os.path.join(assets_dir, "bamboo.png"))
bamboo_length = int(
self.length * 2 * self.screen_width / (self.x_threshold * 2)
)
self.bamboo_img = pygame.transform.scale(self.bamboo_img, (20, bamboo_length))
self._pygame_initialized = TrueHere, we initialize TurtleBambooEnv and define _initialize_pygame, which sets up and loads the images from assets_dir.
A lot of this code was inspired by CartPoleEnv. For example, here’s how its render function starts:
def render(self):
if self.render_mode is None:
assert self.spec is not None
gym.logger.warn(
"You are calling render method without specifying any render mode. "
"You can specify the render_mode at initialization, "
f'e.g. gym.make("{self.spec.id}", render_mode="rgb_array")'
)
return
try:
import pygame
from pygame import gfxdraw
except ImportError as e:
raise DependencyNotInstalled(
'pygame is not installed, run `pip install "gymnasium[classic-control]"`'
) from e
if self.screen is None:
pygame.init()
if self.render_mode == "human":
pygame.display.init()
self.screen = pygame.display.set_mode(
(self.screen_width, self.screen_height)
)
else: # mode == "rgb_array"
self.screen = pygame.Surface((self.screen_width, self.screen_height))
if self.clock is None:
self.clock = pygame.time.Clock()
world_width = self.x_threshold * 2
scale = self.screen_width / world_width
polewidth = 10.0
polelen = scale * (2 * self.length)
cartwidth = 50.0
cartheight = 30.0By refactoring the setup into _initialize_pygame, we keep our initialization clean while maintaining the same physics and proportions as the original CartPole. Now, all that’s left is implementing the render function to bring our TurtleBamboo environment to life!
def render(self):
if self.render_mode is None:
return None
if not self._pygame_initialized:
self._initialize_pygame()
import pygame
assert self.turtle_img and self.bamboo_img
# Fill the screen with light blue
self.screen.fill((173, 216, 230))
# Calculate turtle position
turtle_x = int(
self.screen_width / 2.0
+ (self.state[0] / self.x_threshold) * self.screen_width / 2.0
)
turtle_y = int(self.screen_height - 20)
# Draw turtle
turtle_rect = self.turtle_img.get_rect()
turtle_rect.midbottom = (turtle_x, turtle_y)
self.screen.blit(self.turtle_img, turtle_rect)
# Draw bamboo
pivot_y = turtle_y - turtle_rect.height / 2
angle_degrees = np.degrees(self.state[2])
rotated_bamboo = pygame.transform.rotate(self.bamboo_img, angle_degrees)
bamboo_rect = rotated_bamboo.get_rect()
# Position bamboo
angle_rad = math.radians(angle_degrees)
offset_x = -math.sin(angle_rad) * (self.bamboo_img.get_height() / 2)
offset_y = -math.cos(angle_rad) * (self.bamboo_img.get_height() / 2)
bamboo_rect.center = (int(turtle_x + offset_x), int(pivot_y + offset_y))
self.screen.blit(rotated_bamboo, bamboo_rect)
if self.render_mode == "human":
pygame.event.pump()
self.clock.tick(self.metadata["render_fps"])
pygame.display.flip()
return None
elif self.render_mode == "rgb_array":
return np.transpose(
np.array(pygame.surfarray.pixels3d(self.screen)), axes=(1, 0, 2)
)Yet again, we took a lot of inspiration from CartPoleEnv, especially for calculating the position of the bamboo.
To load the environment like other native environment in Gymnasium, we need to register it:
# Register the environment
register(
id="TurtleBamboo-v0",
entry_point=TurtleBambooEnv,
max_episode_steps=500,
)After registering the environment, we can make a random run with it (just like CartPole) and get:

A cute turtle that doesn’t really know how to balance the stick!
This is just a glimpse of what possible with custom environment, and you can learn a lot more in the official Gymnasium tutorial.
The problem with continuous state spaces
Now that we’ve customized our environment, it’s time to train the turtle to balance the bamboo. We’ll use Q-Learning, just like in the previous post.
But there’s a big problem — Q-Learning requires a finite number of states to learn an optimal policy. It works well in environments like CliffWalking, where the state space is small and discrete. However, in TurtleBamboo, the state space is continuous, meaning there are infinitely many possible states. How can we apply Q-Learning in such a scenario?
As the title of this post suggests, the answer is discretization. We’ll divide the continuous state space into discrete bins, effectively turning it into a manageable set of finite states that Q-Learning can work with.
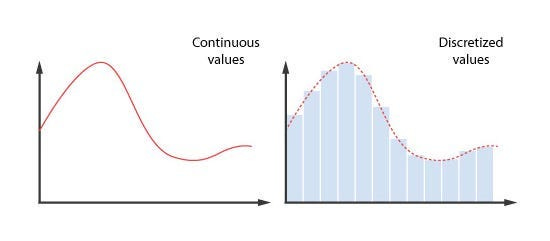
At least for me, this was one of those concepts that felt easy to understand in theory but tricky to implement correctly. So, let’s break it down and see how to do it step by step!
Training Our Turtle With Q-Learning
The training process will be similar to the previous post, with the main changes focusing on learning parameters and state space discretization.
import gymnasium as gym
import numpy as np
from tqdm import tqdm
import turtle_bamboo_env
# Training parameters
LEARNING_RATE = 0.1
DISCOUNT_FACTOR = 0.99
EPISODES = 50000
EPSILON_DECAY_RATE = 1 / EPISODES
# State space discretization
POS_SPACE = np.linspace(-2.4, 2.4, 10)
VEL_SPACE = np.linspace(-4, 4, 10)
ANGLE_SPACE = np.linspace(-0.2095, 0.2095, 10)
ANGLE_VEL_SPACE = np.linspace(-4, 4, 10)
def digitize_state(state):
pos, vel, angle, angle_vel = state
pos_d = np.digitize(pos, POS_SPACE)
vel_d = np.digitize(vel, VEL_SPACE)
angle_d = np.digitize(angle, ANGLE_SPACE)
angle_vel_d = np.digitize(angle_vel, ANGLE_VEL_SPACE)
return pos_d, vel_d, angle_d, angle_vel_d
def train_episode(env, epsilon, q_table):
state, _ = env.reset()
digitized_state = digitize_state(state)
terminated = truncated = False
rewards = 0
while not terminated and not truncated and rewards < 1000:
# Choose action (epsilon-greedy)
if np.random.uniform() < epsilon:
action = env.action_space.sample()
else:
action = np.argmax(q_table[*digitized_state, :])
# Take action
next_state, reward, terminated, truncated, _ = env.step(action)
next_digitized_state = digitize_state(next_state)
rewards += float(reward)
# Update Q-table
q_table[*digitized_state, action] += LEARNING_RATE * (
reward
+ DISCOUNT_FACTOR * np.max(q_table[*next_digitized_state, :])
- q_table[*digitized_state, action]
)
state = next_state
digitized_state = next_digitized_state
return int(rewards)
def train():
env = gym.make("TurtleBamboo-v0")
# Initialize Q-table
q_table = np.zeros(
(
len(POS_SPACE) + 1,
len(VEL_SPACE) + 1,
len(ANGLE_SPACE) + 1,
len(ANGLE_VEL_SPACE) + 1,
env.action_space.n if hasattr(env.action_space, "n") else 2,
)
)
rewards_per_episode = np.zeros(EPISODES)
epsilon = 1
for i in tqdm(range(EPISODES), desc="Training Episodes"):
rewards_per_episode[i] = train_episode(env, epsilon, q_table)
epsilon = max(epsilon - EPSILON_DECAY_RATE, 0)
if i > 0 and i % 1000 == 0:
last_100 = np.sum(rewards_per_episode[i + 1 - 100 : i + 1]) / 100
tqdm.write(
f"Episode {i+1}/{EPISODES}, Average reward (last 100): {last_100:.2f}"
)
if last_100 > 500:
tqdm.write(f"Found solution in {i} episodes with reward {last_100}")
break
env.close()
return q_table, rewards_per_episode
if __name__ == "__main__":
q_table, rewards_per_episode = train()
np.save("turtle_bamboo_q_table.npy", q_table)
np.save("turtle_bamboo_rewards.npy", rewards_per_episode)After we will run it, we will get q_table with perfect (or almost perfect) score of 500. The key part here is the discretization that we used to split each range into 10 bins with np.digitize. To get the ranges, I took some of them from the Documentation and some from empirical checks.
After we digitize the continuous state space, the Q-learning algorithm can treat it as a finite set of discrete states, making it feasible to store and update values in a Q-table (important note, I used syntax that works only from python3.11, so please use it if you want to run the program).
Each step, the agent:
1. Observes its current (digitized) state.
2. Chooses an action based on an epsilon-greedy policy.
3. Takes the action, receiving a reward and the next state.
4. Updates the Q-table using the Bellman equation.
Since the reward in CartPole is given per timestep survived, a well-trained turtle will learn to balance the bamboo for as long as possible, eventually achieving a near-perfect score of 500.
This approach works well, but a larger number of bins (e.g., 20 or 50 instead of 10) could potentially improve performance — at the cost of a larger Q-table and slower learning.
Final Thoughts: A Turtle That Learns
We’ve taken a classic reinforcement learning environment, CartPole, and transformed it into a fun and visually engaging TurtleBamboo challenge. Along the way, we explored two crucial RL techniques: environment customization and state discretization.
By customizing Gymnasium’s CartPole environment, we demonstrated how to modify an existing environment to create something unique while preserving the underlying physics. Then, by discretizing the continuous state space, we adapted Q-Learning — an algorithm designed for discrete environments — to train our turtle effectively.
At first, our turtle struggled to balance the bamboo, but through thousands of training episodes, it eventually mastered the task, achieving the maximum score of 500!
What’s Next? Now that our turtle has mastered the art of bamboo balancing, why stop here? Try tweaking the environment, experimenting with different RL algorithms, or even designing your own custom challenge! If you found this project fun or have ideas for improvements or other future posts, let me know in the comments — I’d love to hear your thoughts!
Thanks, Shmulik! I really enjoyed this creative deep dive into discretization and environment customization. The TurtleBamboo twist is both fun and insightful — a great way to make RL more engaging. Looking forward to your next post!
Great read, thank you!